How to Deploy Whisper to Production (~1 MIN!)
September 16, 2022
Deprecated: This blog article is deprecated. We strive to rapidly improve our product and some of the information contained in this post may no longer be accurate or applicable. For the most current instructions on deploying a model like Whisper to Banana, please check our updated documentation.
You could also check out our Whisper demo repo on Github to get started quickly.
In this video walkthrough we show you the quickest method to deploy Whisper to production on serverless GPUs.
This deployment is lightning fast because we published a 1-click model of Whisper for all Banana users to enjoy. These 1-click models are available within your Banana Dashboard and are callable in production in ~1 minute. Simply select "New Models" and then choose "Instant Deploy from a Template".
Currently, we have two 1-click models available: Whisper and Stable Diffusion.
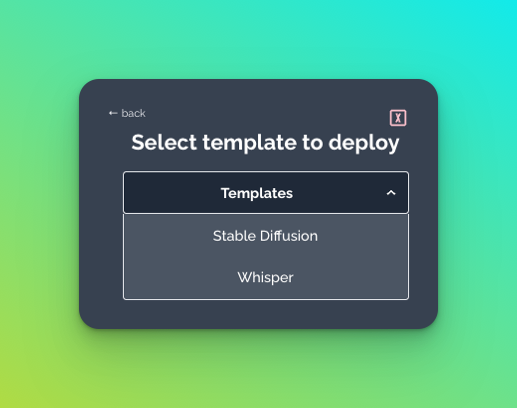
This deployment demo is completed in about 4 minutes, but in reality the actual deployment takes ~1 minute to complete. The remainder of the video we demonstrate how to run an inference in production with Whisper on serverless GPUs using a virtual environment.
What is Whisper?
Whisper is an open-source speech recognition machine learning model developed by OpenAI that understands and transcribes audio into text at a comprehension level comparable with humans. Whisper can transcribe and translate audio in multiple languages.
Tutorial Notes & Resources:
We mentioned a few resources and links in the tutorial, here they are.
- Creating a Banana account (click Sign Up).
- Reference to the Whisper serverless template repo.
In the tutorial we used a virtual environment on our machine to run our demo model. If you are wanting to create your own virtual environment use these commands (Mac):
- create virtual env:
python3 -m venv venv - start virtual env:
source venv/bin/activate - packages to install:
pip install banana_dev pip install diffusers pip install transformers
In Closing:
Let us know what you are building with Whisper! We'd love to know and share your projects that have been deployed with Banana. The best place to reach our team is in our Discord or by tweeting at us on Twitter.