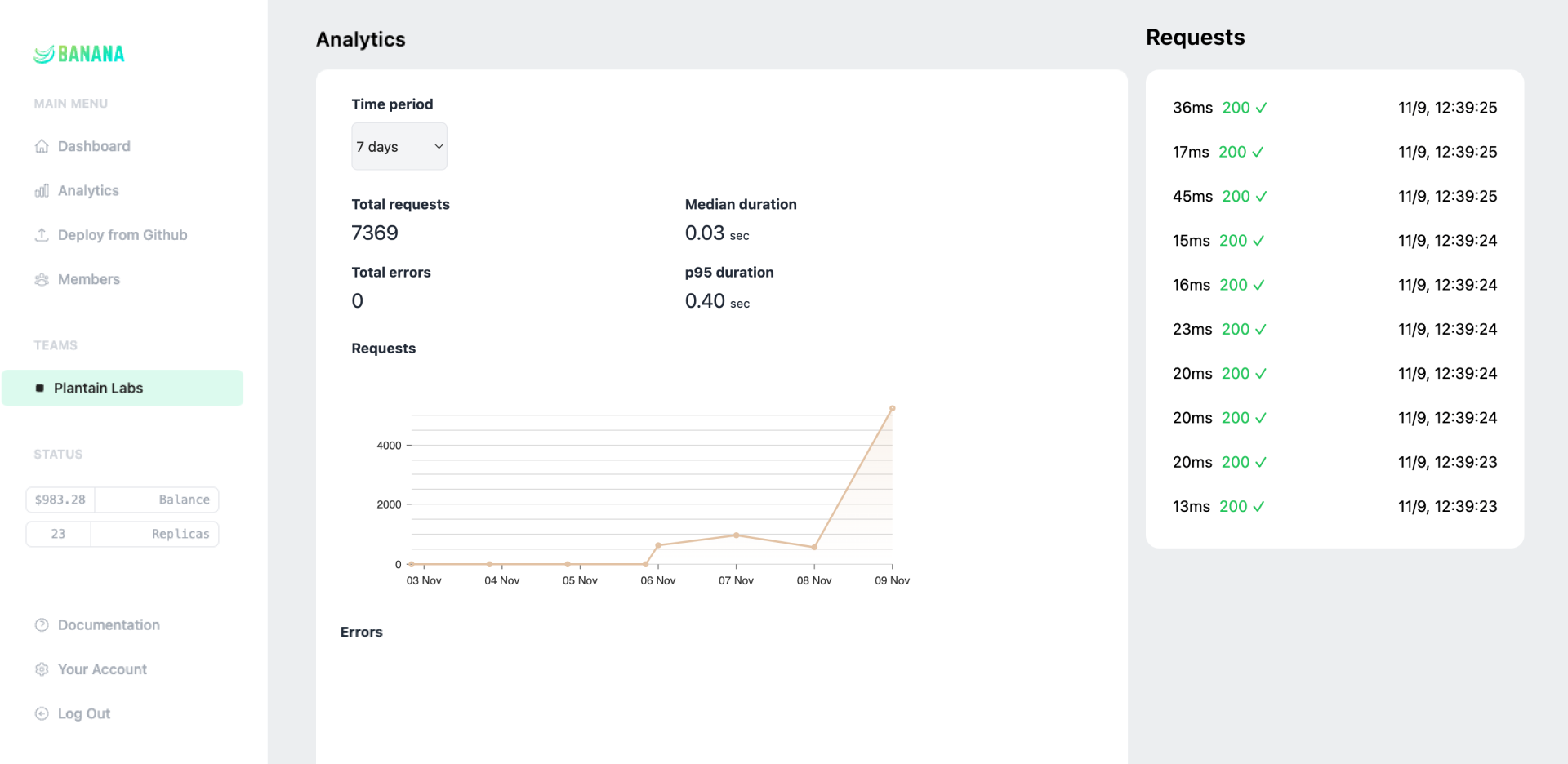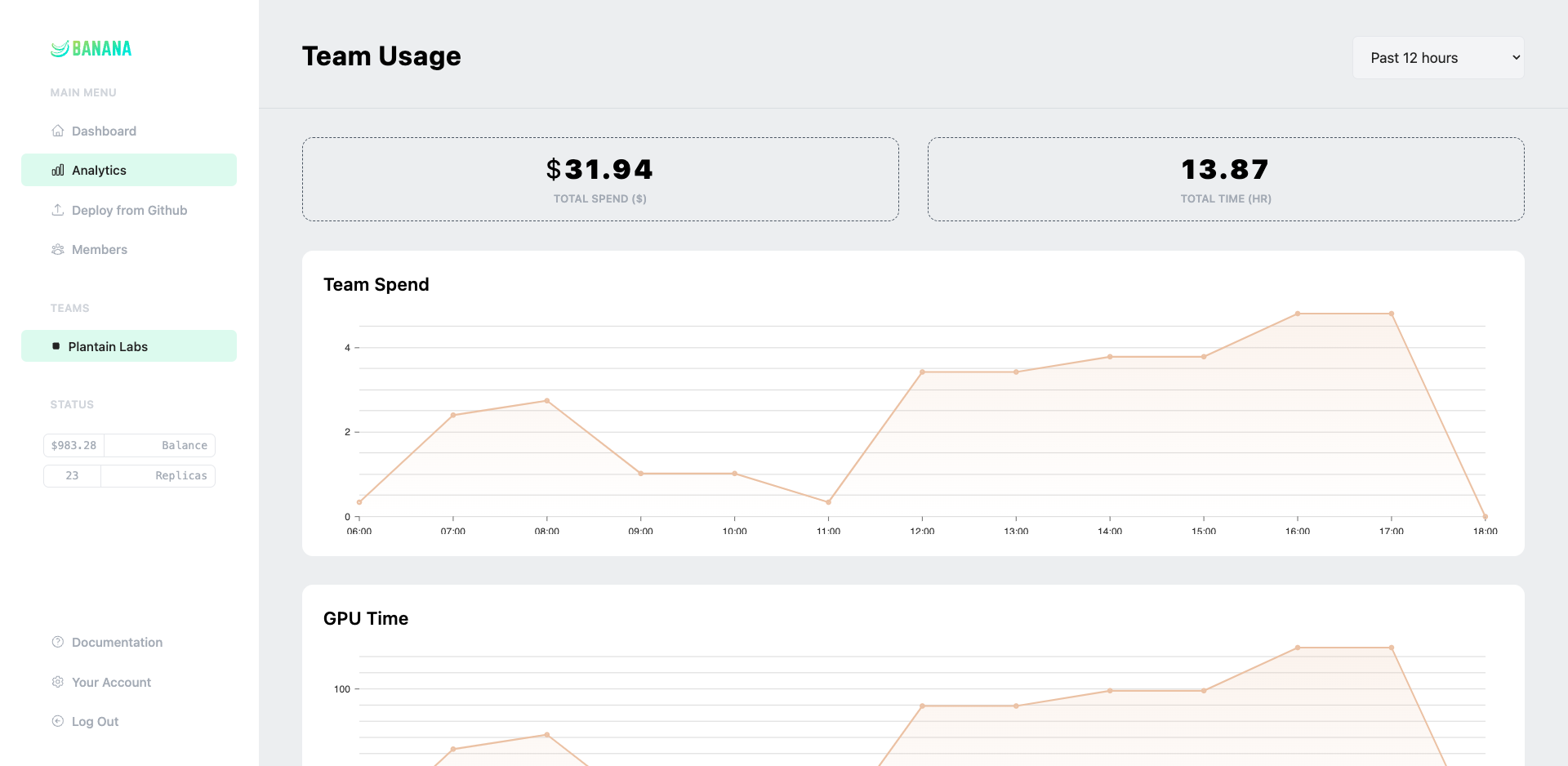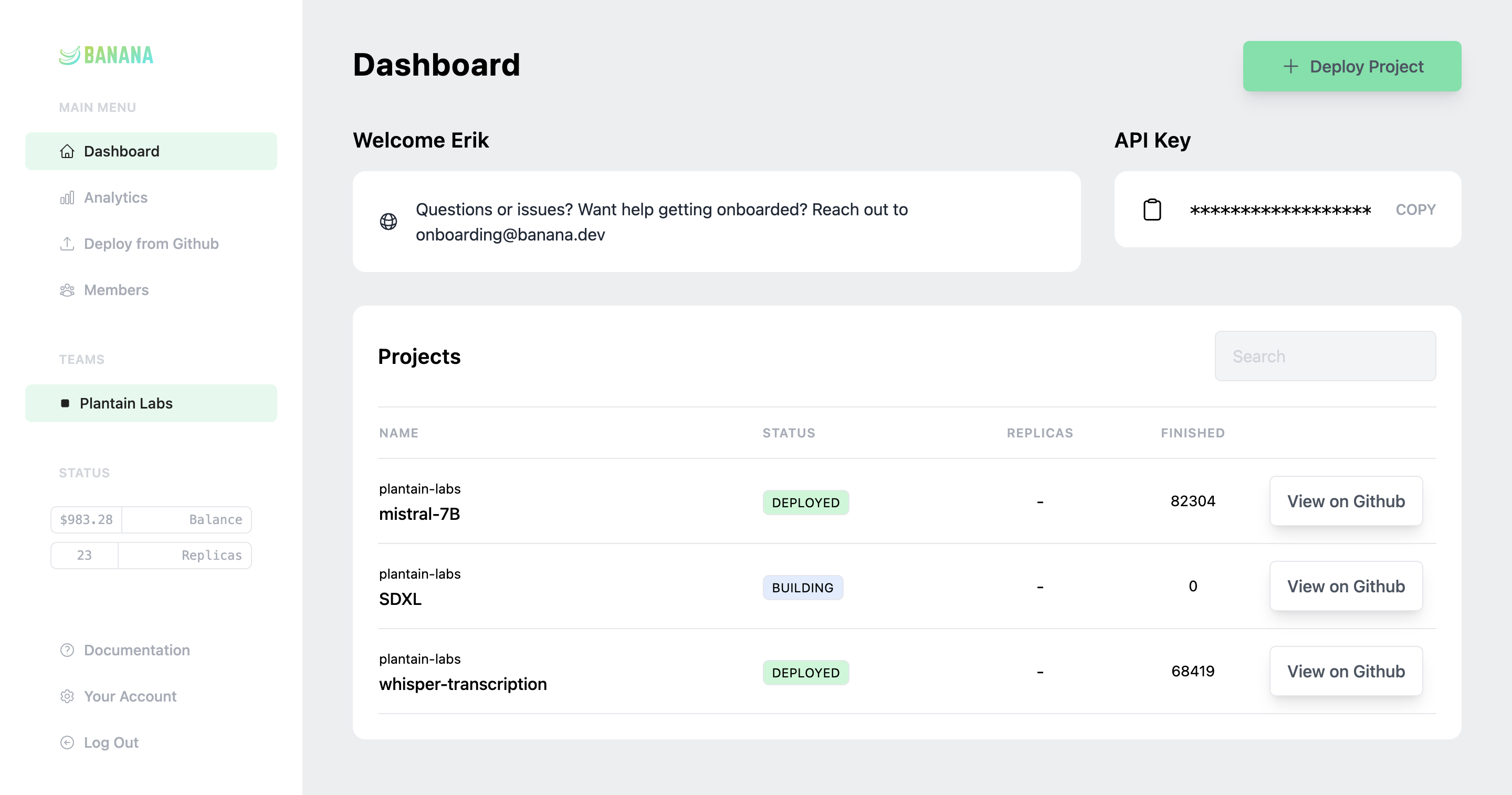

Banana scales your GPUs up and down automatically, keeping costs low and performance high.
Most serverless providers take huge margin on GPU time. Not Banana. We're here to help you scale, not to take a cut.
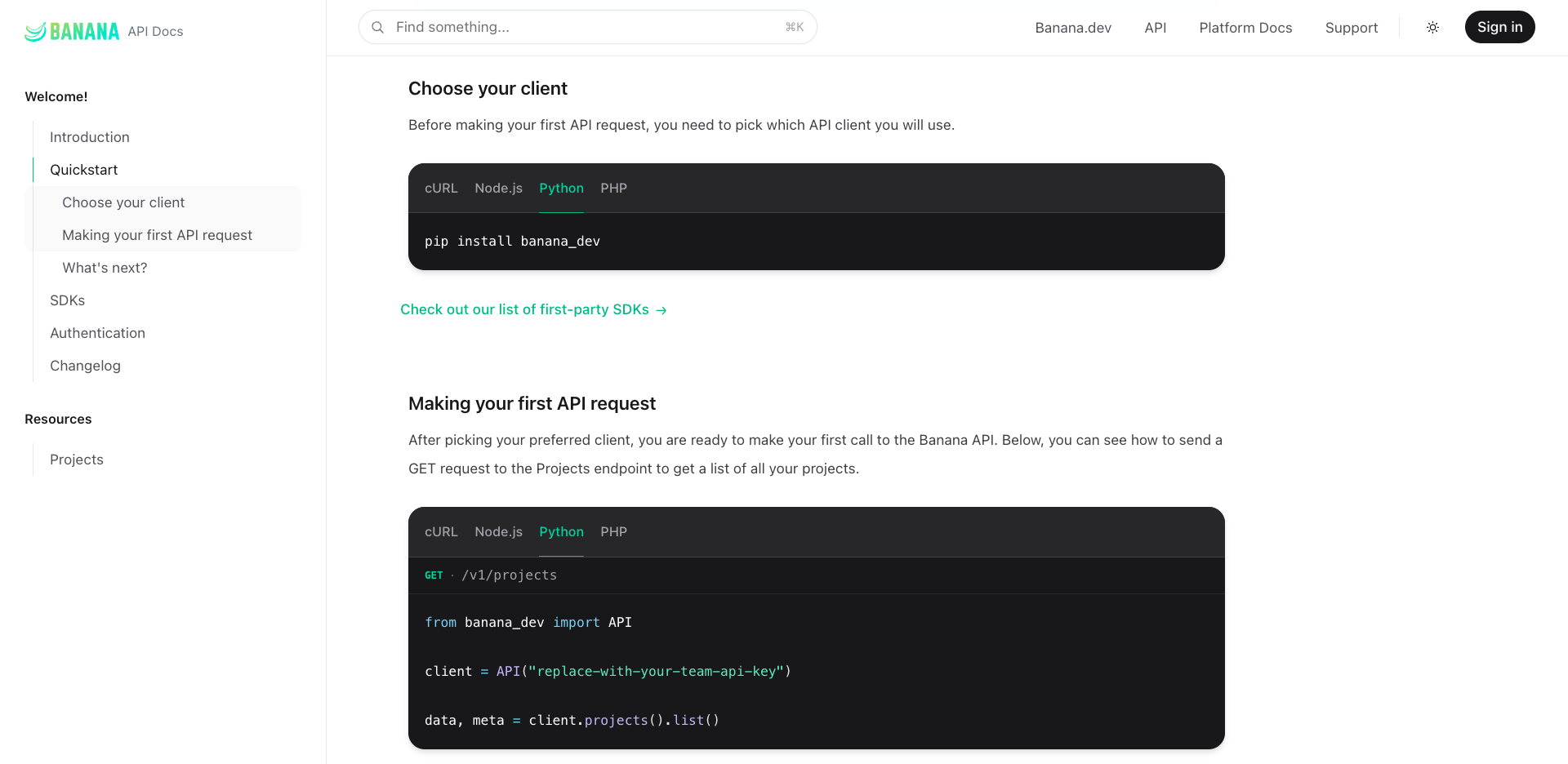
DevOps batteries included. GitHub integration, CI/CD, CLI, rolling deploys, tracing, logs, and more.