How to Deploy GPT-JT to Production on Serverless GPUs
February 22, 2023
Deprecated: This blog article is deprecated. We strive to rapidly improve our product and some of the information contained in this post may no longer be accurate or applicable. For the most current instructions on deploying a model like GPT-JT to Banana, please check our updated documentation.
We're going to walkthrough how you can easily deploy GPT-JT to production. This tutorial is welcoming to all levels of knowledge and experience in AI. We'll be deploying GPT-JT through Banana's deployment framework, which you can consider the "template" to easily run most ML models on serverless GPUs.
We use this GPT-JT model from HuggingFace for the demo. Let's get into it!
What is GPT-JT?
GPT-JT is a fork from GPT-J-6B that was fine-tuned on 3.53 billion tokens, yet it outperforms most 100 billion+ parameter models at classification. Basically, this model packs a freaking punch. It was developed by Together, they have a wonderful release article that explains the model performance details quite well.
Video: GPT-JT Deployment Tutorial
Video Notes & Resources:
We mentioned a few resources and links in the tutorial, here they are.
- Creating a Banana account (click Sign Up).
- GPT-JT Banana template.
In the tutorial we used a virtual environment on our machine to run our demo model. If you are wanting to create your own virtual environment use these commands (Mac):
- create virtual env:
python3 -m venv venv - start virtual env:
source venv/bin/activate - packages to install:
pip install banana_dev
Guide: How to Deploy GPT-JT on Serverless GPUs
1. Fork Banana's GPT-JT Serverless Framework Repo
Fork this repository to your own private repo. A Banana discord member (s/o @lucataco) built this GPT-JT repo for anybody to use. Pretty sweet! Because this repo already is setup for the GPT-JT model this is going to be a super simple tutorial.
That said, we highly recommend that you review the documentation of our Serverless Framework. We breakdown and explain the framework components so you can better understand how it all operates in case you want to deploy other models that may not have as straight forward of a template repo available.
2. Create Banana Account and Deploy FLAN-T5
Now that the GPT-JT repository is cloned into your own private repo, you'll want to test the code before deploying to Banana in production. To do that, we suggest using Brev (follow this tutorial).
Once you have tested, login to your Banana Dashboard and navigate to the "Deploy" tab.
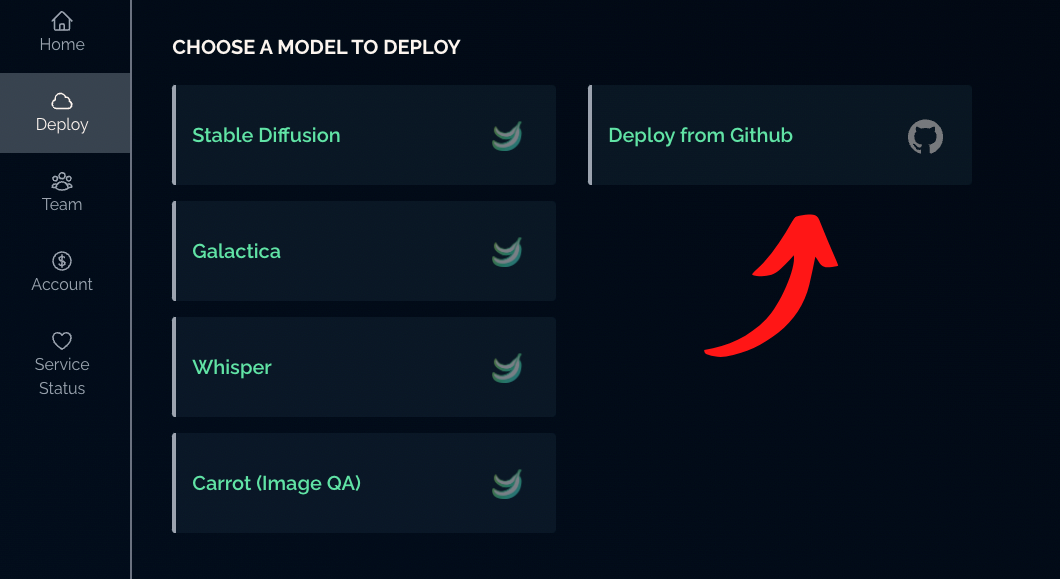
Select "Deploy from GitHub", and choose your GPT-JT repository. Click "Deploy" and the model will start to build. The build process can take up to 1 hour (usually much less) so please be patient.
You'll see the Model Status change from "Building" to "Deployed" when it's ready to be called.
You can also monitor the status of your build in the Model Logs tab.

3. Call your GPT-JT Model
After your model has built, it's ready to run in production! Jump over to the Banana SDK and select the programming language of your choice. Within the SDK you will see example code snippets of how you can call your GPT-JT model.
That's it! Congratulations on running GPT-JT on serverless GPUs. You are officially deployed in production!
Wrap Up
Reach out to us if you have any questions or want to talk about GPT-JT. We're around on our Discord or by tweeting us on Twitter. What other machine learning models would you like to see a deployment tutorial for? Let us know!